
Making Core Dumps Useful
Some pointers on using GDB to analyze core dumps. Follow up article to Making Linux C++ Crashes Less Chaotic.
The linux man page https://man7.org/linux/man-pages/man5/core.5.html gives a basic introduction to the idea of core dumps:
The default action of certain signals is to cause a process to terminate and produce a core dump file, a file containing an image of the process’s memory at the time of termination. This image can be used in a debugger (e.g., gdb(1)) to inspect the state of the program at the time that it terminated. A list of the signals which cause a process to dump core can be found in signal(7).
I’ve found that core dumps tend to be a underutilized tool in C/C++ development. While not quite as good as being able to attach a debugger in realtime and reproduce a crash, a core dump can often give you:
- Where exactly a crash occurred
- All the relevant state (variables, memory, etc.)
- The state of all the threads, not just the one that the crash occurred on
This is a great way to be able to get diagnostics for crashes that don’t have a known method to reproduce, or that only occur in the field.
I think there’s three main problems stopping most developers from taking advantage of them:
- Generating core dumps and finding them after they’re generated is not obvious
- Using GDB at all is a huge learning curve
- There are a lot of “gotchas” that might make the dumps not useful. While everything might just work out of the box, there’s often going to be some weird step specific to your application that will be hard to find. This is especially true when analysing dumps generated on a different computer from the one doing the analysis.
I’ll go through these points in order to give some details on how I’ve addressed them in the past.
Generating core dumps
https://man7.org/linux/man-pages/man5/core.5.html explains that:
There are various circumstances in which a core dump file is not produced
and then goes on to list a page worth of different settings that effect how and where core dumps are generated.
While customizing those files is a reasonable way to go, I’ve found that on modern ubuntu, installing systemd-coredump can be a good simplification.
It offloads the core dump management to systemd where you can use coredumpctl to manage the dumps. They are identified by the crashed process’s PID. Some basic usage:
coredumpctl list- Lists the core dumps on the systemcoredumpctl info -1- Get a description of the last dump with a backtracecoredumpctl debug -1- Start a GDB session in the terminal using the last dumpcoredumpctl dump -1 > core- Generate acorefile from the last dump that can be used by GDB directly
Besides automatically generated core dumps, you can use the gcore command to create a core dump of a running command (I’ve had this crash due to running out of RAM). You can also use kill -3 $PID to send the SIGQUIT to the $PID to which should also generate a core dump.
It’s also worth noting that even embedded systems can generate core dumps, saving them to non-volatile memory, or even dumping them over serial. See https://docs.espressif.com/projects/esp-idf/en/stable/esp32/api-guides/core_dump.html for the core dump features of the ESP32 chip.
Using GDB
Using GDB is a huge topic. It’s difficult to learn both because it is a very complex tool, but also because (in my opinion) it is also very opaque.
For a reasonable basic walkthrough of using GDB you can start with:
- https://developers.redhat.com/articles/the-gdb-developers-gnu-debugger-tutorial-part-1-getting-started-with-the-debugger#
- https://www.cse.unsw.edu.au/~learn/debugging/modules/gdb_coredumps/
I find that for simple tasks, the process is much easier if you can get a visual debugger working through the IDE you’re using for development. My IDE of choice is VSCode, but most major IDE’s will have a similar GDB integration.
For VSCode, you can add a configuration to the launch.json file documented here https://code.visualstudio.com/docs/editor/debugging#_launch-configurations
Here’s a simple example I made to debug https://github.com/axlan/crash_tutorial/blob/master/src/example2/handle_signal.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"name": "Example2 Core Dump",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/example2",
"coreDumpPath": "${workspaceFolder}/core",
"cwd": "${workspaceFolder}",
"MIMode": "gdb",
"externalConsole": false,
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
}
This assumes you have a core dump file core in the root of the project directory.
This is using the cppdbg type which is the Microsoft developed plugin for C++ debugging. There are many others like the “Native Debug” extension, but generally the official one works best. It uses GDB under the hood, and I’ve found that it’s generally customizable enough to cover most use cases. The main issues I’ve had is that it’s not very transparent with what it’s doing and may make assumptions that break down especially for remote debugging, or debugging cross compiled binaries. I’ve found adding the following by adding
1
2
3
4
5
"logging": {
"moduleLoad": true,
"engineLogging": true,
"trace": true
}
can help clarify what it’s doing and what errors it’s hitting.
Once it’s working, the debugger will show you exactly where the crash occurred.
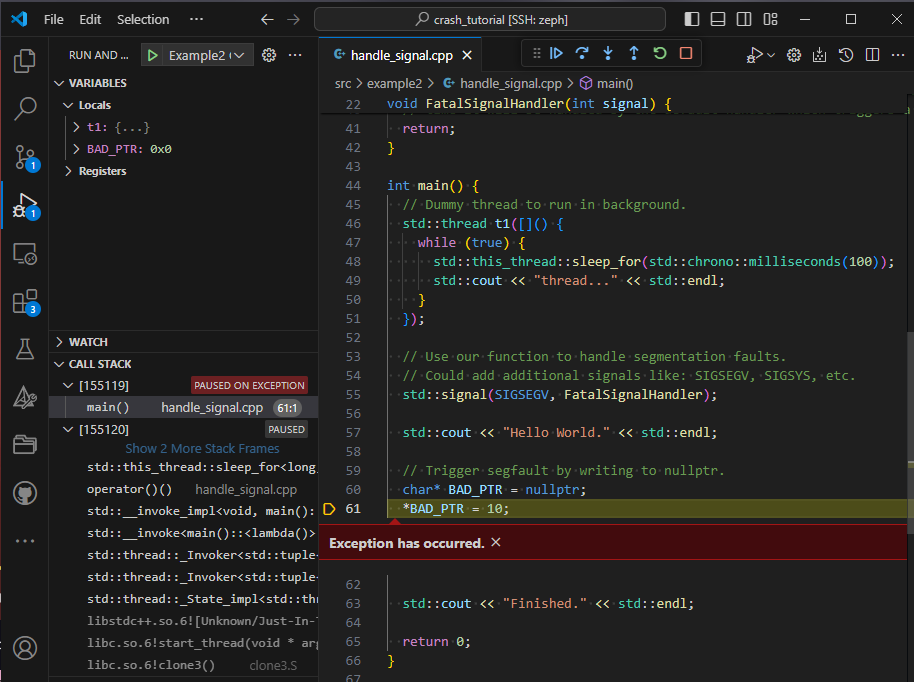
This let’s you use the GUI to jump to other threads, inspect variables, and walk through the call stack. You can also bring up the debug console, to use the GDB CLI directly. Since it’s in MI mode, you either need to use that even more obscure syntax, or start each command with -exec.
Gotchas
Even if you’re generating core dumps and loading them in a debugger, often you’ll find that they won’t point to the source files or resolve any symbols
1
2
(gdb) bt
#0 0x0000000000403550 in main ()
or even worse that it doesn’t appear to give any meaningful information at all.
1
2
3
4
(gdb) bt
#0 0x0000aaaacab2cd50 in ?? ()
#1 0x0000000000000038 in ??
Backtrace stopped: previous frame identical to this frame (corrupt stack?)
Missing Debug Symbols in Application Binary
The easiest class of problems is that the binary was compiled without debug symbols, or with too high an optimization level.
First, the debug symbols https://gcc.gnu.org/onlinedocs/gcc/Debugging-Options.html. For most use cases, you can just include the -g flag. This builds your binary with the metadata needed to map symbols back to your source code. This means getting variable names and line numbers.
The cost of this flag is that the binary will be bigger, sometimes much bigger. There are two approaches to try to get the best of both worlds:
- You can compress the symbols in the binary (
-gz=zlib). This can make debugging slower, but it otherwise pretty much invisible. - You can strip the symbols out of the binary, but keep them around somewhere to use for debugging.
See https://sourceware.org/gdb/current/onlinedocs/gdb.html/Separate-Debug-Files.html and https://stackoverflow.com/questions/46197810/separating-out-symbols-and-stripping-unneeded-symbols-at-the-same-time for discussions on separating the debug symbols from the binary.
Alternatively, you can just save the original binary with symbols and use that for debugging a core dump generated from a stripped binary.
Professionally, I’ve made systems to upload the debug symbols for releases as part of CI, and made tools to automatically download them as needed for debugging.
Important Sections are Optimized Out
Assuming the debug symbols are present, you may also have difficulty debugging if the optimization level is too high. Here, you need to trade off performance of your application, with ease of debugging.
I’ve typically had a reasonable time debugging with the optimization flag -O2, and the recommended flag is -Og. To leave the code as direct a map to the source as possible you can use -O0, but that typically comes at a pretty steep performance penalty.
https://stackoverflow.com/questions/7493947/whats-the-best-g-optimization-level-when-building-a-debug-target is another discussion of these trade offs.
GDB is not Able to Find Symbols in Binaries
This is an issue I’ve often when debugging cross compiled binaries either remotely, or through a core dump. I initially assumed, I only needed symbols for the code I was debugging, but I’d run into problems unwinding the stack if the crash was in the glibc code.
GDB by default assumes that the paths used at runtime to resolve libraries, match the ones being used during debugging. This is often totally wrong when debugging core dumps from other systems, especially if they were crossed compiled. Presumably, this can be avoided somewhat if you include the file backed mappings as described under the “Controlling which mappings are written to the core dump” section in core man page, but that might make the dumps prohibitively large.
There may be a better way to do this, but I’ve found the easiest way to fix missing symbol files is to copy over whatever libraries are needed and reconstruct their path structure under some local directory. You can them use the set sysroot GDB command to indicate to GDB where to search for library files. I found this was also needed when my application was considered a “file backed mapping” and wasn’t being loaded from the binary I passed to GDB: https://stackoverflow.com/questions/78084814/how-can-i-set-the-path-of-a-file-backed-mapping-for-a-core-dump-in-gdb
For setting up typical cross compiler settings for VSCode, I’ve had to set the following additional paramters as part of the cppdbg configuration.
1
2
3
4
5
6
7
8
9
10
11
12
{
"miDebuggerPath": "/usr/bin/gdb-multiarch",
"sourceFileMap": {
"/proc/self/cwd/": "${workspaceFolder}"
},
"setupCommands": [
{
"description": "Set sysroot $HOME/src/nautilus/",
"text": "set sysroot $HOME/src/nautilus/"
}
],
}
I’m sure there are plenty of other gotchas, but these are some that I’ve had to work through in my recent projects.